[HPC Architecture Development]
Conceptual Approach
단일 노드의 컴퓨터 시스템의 성능을 향상시키는 방법에 대한 많은 연구가 있었습니다. 결론은 (1) 프로세서의 성능을 개선하는 방안, (2) 프로세서의 숫자를 늘리는 방안, (3) 다수의 시스템을 연계하는 방안으로 귀결됩니다. 현실적으로 (1)에 따라 프로세서의 성능을 개선하는 입장이 되는 것은 불가능하고, (3)에 따라 시스템의 수를 늘리는 Clustering 방법론은 개발하고자 하는 기술의 방향에 부합하지 않습니다.
(2)의 방안은 이미 많은 연구와 성과가 있습니다. 초창기에는 시스템버스를 확장하여 다수의 프로세서를 하나의 보드에 장착하는 기술이 현실화되었고, 이후에는 하나의 프로세서에 다수의 프로세서코어를 집적하는 방향으로 확대 되었습니다. 그러나 시장의 요구는 몇 배의 성능개선이 아니라 수천 배의 성능 개선이어서 시장의 요구에는 미달한 것입니다.
우리는 PCIe이 Bus system이 아니고 Channel Bonding이 가능한 Point-to-Point Network이라 점과 PCIe에 장착되는 GPU나 FPGA가 연산가속기로 활용된다는 점에 착안하여 PCIe Switching Subsystem이 시스템 성능을 향상시키는 현실적인 방안임을 확신하고 기술개발에 착수 하였습니다.
이러한 대규모의 연결로 단위 시스템의 성능을 극적으로 향상시킬 수 있음을 제품으로 증명하였습니다. 이는 Intraconnection으로 보아도 무방합니다.
(2)의 방안은 이미 많은 연구와 성과가 있습니다. 초창기에는 시스템버스를 확장하여 다수의 프로세서를 하나의 보드에 장착하는 기술이 현실화되었고, 이후에는 하나의 프로세서에 다수의 프로세서코어를 집적하는 방향으로 확대 되었습니다. 그러나 시장의 요구는 몇 배의 성능개선이 아니라 수천 배의 성능 개선이어서 시장의 요구에는 미달한 것입니다.
우리는 PCIe이 Bus system이 아니고 Channel Bonding이 가능한 Point-to-Point Network이라 점과 PCIe에 장착되는 GPU나 FPGA가 연산가속기로 활용된다는 점에 착안하여 PCIe Switching Subsystem이 시스템 성능을 향상시키는 현실적인 방안임을 확신하고 기술개발에 착수 하였습니다.
이러한 대규모의 연결로 단위 시스템의 성능을 극적으로 향상시킬 수 있음을 제품으로 증명하였습니다. 이는 Intraconnection으로 보아도 무방합니다.
Originated Method
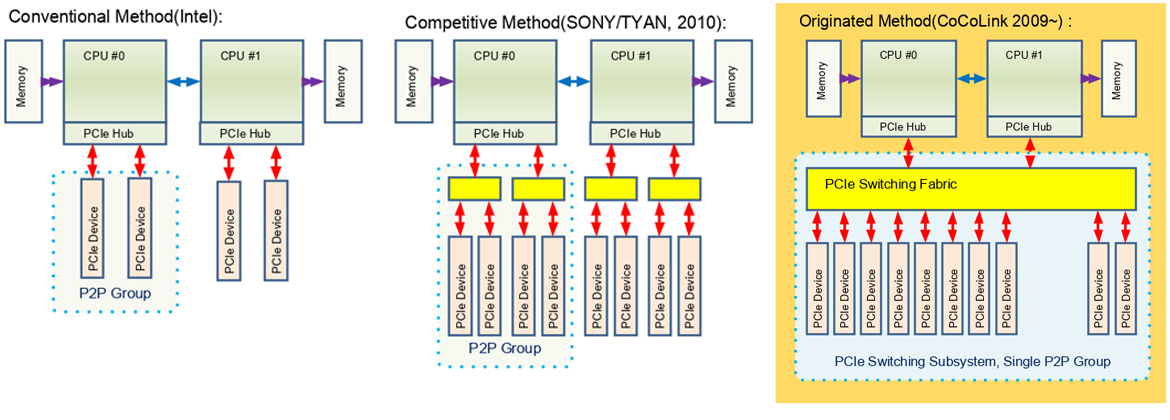
Klimax-210은 기존의 시스템과는 달리 PCIe Fabric이 시스템의 중추적인 역할을 하여 CPU의 종류나 수에 상관없이 다수의 PCIe 디바이스를 장착할 수 있습니다.
기존의 시스템에서는 PCIe slot의 수에도 제한이 있을 뿐 아니라 그 PCIe Slot들이 두 개의 그룹으로 나누어져 있어 그룹이 다른 디바이스 간의 직접적인 데이터 교환(P2P)에도 제약이 있었습니다.
이에 반하여 Klimax-210은 960Gbps 밴드위스의 PCIe Fabric을 통하여 모든 디바이스와 연결되며 CPU의 수에 구애 받지 않고 충분한 디바이스 접속에도 모든 디바이스간에 P2P가 지원되는 이상적인 디바이스접속 구조를 확립하였습니다. 이러한 이유로 CPU가 하나만 탑재되어도 20대의 PCIe x16 디바이스를 탑재할 수 있고 이를 이용하는데 아무런 제약이 없습니다. 이러한 기술을 통하여 Klimax-210은 다른 시스템이 따라올 수 없는 고성능의 연산용 컴퓨팅 머신이 됩니다. 또한 이러한 장점은 CPU와 CPU보드의 수를 줄여 전체시스템의 비용을 획기적으로 절감할 수 있습니다.
기존의 시스템에서는 PCIe slot의 수에도 제한이 있을 뿐 아니라 그 PCIe Slot들이 두 개의 그룹으로 나누어져 있어 그룹이 다른 디바이스 간의 직접적인 데이터 교환(P2P)에도 제약이 있었습니다.
이에 반하여 Klimax-210은 960Gbps 밴드위스의 PCIe Fabric을 통하여 모든 디바이스와 연결되며 CPU의 수에 구애 받지 않고 충분한 디바이스 접속에도 모든 디바이스간에 P2P가 지원되는 이상적인 디바이스접속 구조를 확립하였습니다. 이러한 이유로 CPU가 하나만 탑재되어도 20대의 PCIe x16 디바이스를 탑재할 수 있고 이를 이용하는데 아무런 제약이 없습니다. 이러한 기술을 통하여 Klimax-210은 다른 시스템이 따라올 수 없는 고성능의 연산용 컴퓨팅 머신이 됩니다. 또한 이러한 장점은 CPU와 CPU보드의 수를 줄여 전체시스템의 비용을 획기적으로 절감할 수 있습니다.
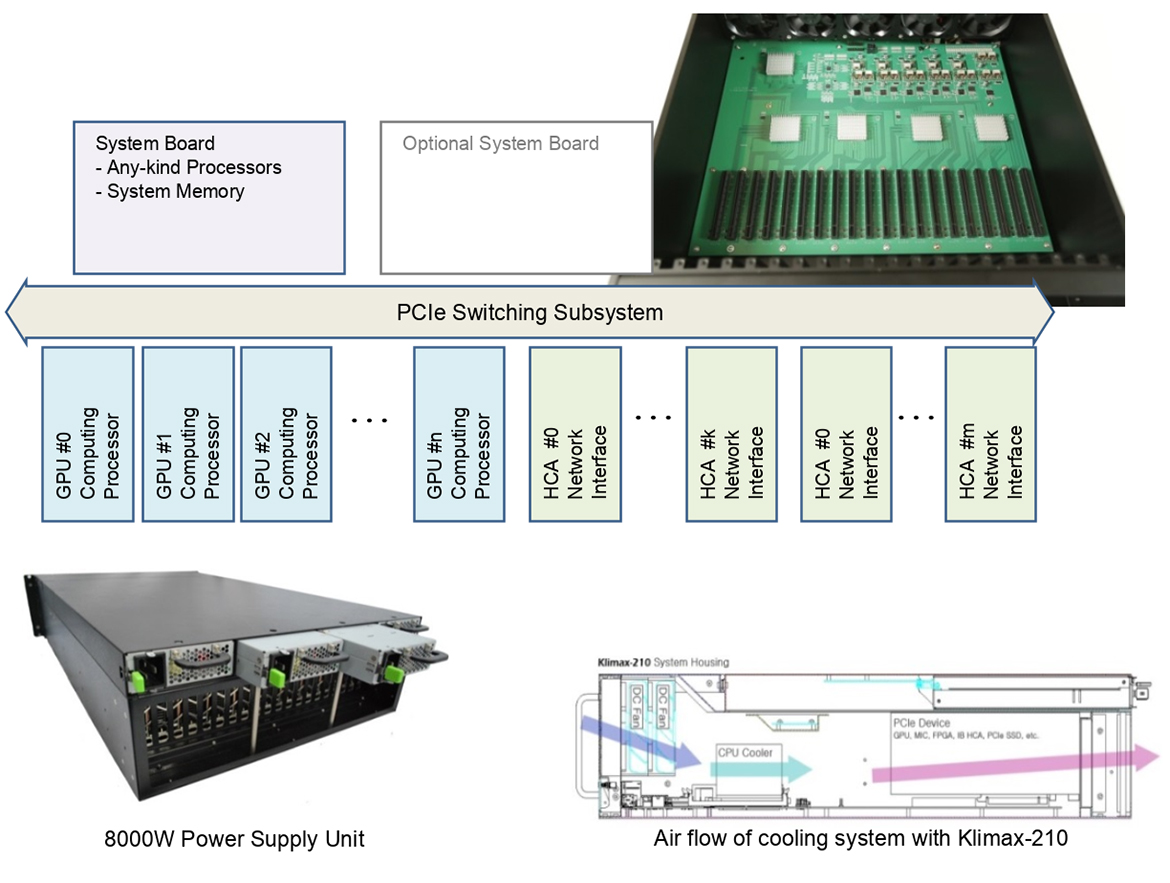
PCIe Switching Subsystem
Board to Board type of PCIe Switching Subsystem has been applied to Klimax-210 to maintain a very stable connection. The number of PCIe devices that can be equipped in a PCIe Switching Fabric has been remarkably expanded as well.
20 of PCIe Gen.3 x 16 slots are provided and powerful performance which was unthinkable in the conventional systems is now feasible by installing up to 20 of high-performance accelerating processors such as Tesla P100 PCIe.
20 of PCIe Gen.3 x 16 slots are provided and powerful performance which was unthinkable in the conventional systems is now feasible by installing up to 20 of high-performance accelerating processors such as Tesla P100 PCIe.
GPU Centric Methodology
To overcome performance degradation due to performance differences between CPU and GPU and data bottlenecks, the programming methodology computed only by GPUs ground.
Compact Design
On the inside of Klimax-210, system board, PCIe Switching Fabric board, space for 20 of PCIe devices and 8,000W Power supply are integrated in 4U form-factor to increase spatial efficiency.
10 of Klimax-210 can be equipped in 42" Rack allowing 0.3 PetaFlops per Rack to be integrated. Various equipment for convenience is available to maximize operational convenience.
10 of Klimax-210 can be equipped in 42" Rack allowing 0.3 PetaFlops per Rack to be integrated. Various equipment for convenience is available to maximize operational convenience.
Robust Design and Optimal Cooling System
Robust design for the system integration keeps the structure in a very stable condition using 8,000W(2,000W x 4). The 8,000W power supply will not fall short, even if the system has 20 units of GPU processors with highest performance which requires great power. This enables the system to maintain a stable status even though the system is operated with full load for a long period.
It has an efficient refrigerant flow that uses six 120mm fans for cooling. The six fans and thermo-fluid structure keep the internal temperature stable below 80 degrees Celsius even under high stress situations. If you need more stable cooling method, optional module which consists of 5 x 80mm fans is available. Also it was designed to apply white oil or fluorine container compounds without changing the structure.
Advanced Structural Design for compact form-factor and cooling High Reliability (No cabling)
It has an efficient refrigerant flow that uses six 120mm fans for cooling. The six fans and thermo-fluid structure keep the internal temperature stable below 80 degrees Celsius even under high stress situations. If you need more stable cooling method, optional module which consists of 5 x 80mm fans is available. Also it was designed to apply white oil or fluorine container compounds without changing the structure.
Advanced Structural Design for compact form-factor and cooling High Reliability (No cabling)
[Optimal Programming]
CPU vs. GPU
CPU는 SISD구조이거나 이를 병렬화한 MIMD의 구조를 가지며, 일부 최신 CPU Processor는 성능을 향상시키기 위하여 ALU에 vector engine을 적용하였는데 이는 기계적 성능은 높으나 실제로 프로그래밍할 때 계산성능의 효율을 높이기 매우 어렵습니다. 특히 프로세서 코어가 많아질 경우 성능효율을 높이기 더욱 어렵습니다.
GPU는 SIMD구조인 기존의 Vector Processor를 유연하게 개선하여 MIMD와 유사하게 운영이 가능하게 한 고효율의 Processor로 SPMD로 부르기도 합니다. CPU보다는 월등히 정교한 프로그래밍이 가능하여 월등히 높은 성능효율을 구현할 수 있습니다. 일반적으로 동일한 이론 성능을 보이는 CPU와 GPU는 10배 이상의 실시 성능의 차이가 있습니다.
GPU는 SIMD구조인 기존의 Vector Processor를 유연하게 개선하여 MIMD와 유사하게 운영이 가능하게 한 고효율의 Processor로 SPMD로 부르기도 합니다. CPU보다는 월등히 정교한 프로그래밍이 가능하여 월등히 높은 성능효율을 구현할 수 있습니다. 일반적으로 동일한 이론 성능을 보이는 CPU와 GPU는 10배 이상의 실시 성능의 차이가 있습니다.
GPU Accelerating Computing vs. GPU Centric Computing
GPU Accelerating Computing은 기본적으로 CPU에서 처리하고 처리량이 많은 일부 연산을 GPU에서 처리하는 방식입니다, 이 경우, CPU-GPU간의 데이터 전송에 많은 리소스가 소모되어 전체적인 성능효율이 크게 낮습니다.
GPU Centric Computing은 모든 연산을 GPU가 처리하고 입출력과 프로그램제어 기능만을 CPU에서 처리하는 방식으로 상대적으로 성능효율이 낮은 CPU를 연산에서 배제하여 프로그램 성능을 극대화하기에 매우 유리합니다.
GPU Centric Computing은 모든 연산을 GPU가 처리하고 입출력과 프로그램제어 기능만을 CPU에서 처리하는 방식으로 상대적으로 성능효율이 낮은 CPU를 연산에서 배제하여 프로그램 성능을 극대화하기에 매우 유리합니다.
GPU Centric Computing over PCIe Switching Fabric
GPU Centric Computing의 방법론을 다수의 GPU가 탑재된 시스템에서 운영하는 경우 GPU간에 직접적으로 데이터를 전송하면 극단적으로 성능효율이 높은 컴퓨팅환경을 구성할 수가 있습니다.
시스템에 탑재된 모든 GPU나 SSD, HCA간에 ‘단일 블록의 P2P 데이터 전송’이 가능한 Klimax-210은 이상적인 프로그래밍 환경인 ‘P2P가 지원되는 다수 GPU기반의 GPU Centric Computing’을 가능하게 하는 유일한 시스템입니다.
시스템에 탑재된 모든 GPU나 SSD, HCA간에 ‘단일 블록의 P2P 데이터 전송’이 가능한 Klimax-210은 이상적인 프로그래밍 환경인 ‘P2P가 지원되는 다수 GPU기반의 GPU Centric Computing’을 가능하게 하는 유일한 시스템입니다.
Futuristic Environment for Exa-scale Super-computing
GPU Centric Methodology와 PCIe Switching Fabric을 적용하는 경우, 현재의 GPU 기술만으로도 1 ExaFLOPS 규모의 시스템을 쉽게 구축할 수 있습니다. 나아가 10%에 미치지 못하는 기존 시스템의 성능효율을 50% 이상으로 높일 수 있으므로 실질적으로는 10 ExaFLOPS 성능의 시스템의 효용성을 얻을 수 있습니다.
CoCoLink Sugests GPU Centric Computing Methodology
코코링크는 GPU Centric Computing 방법론에 있어서 이 방법론을 제안한 기업으로 최고의 역량을 보유하고 있습니다.
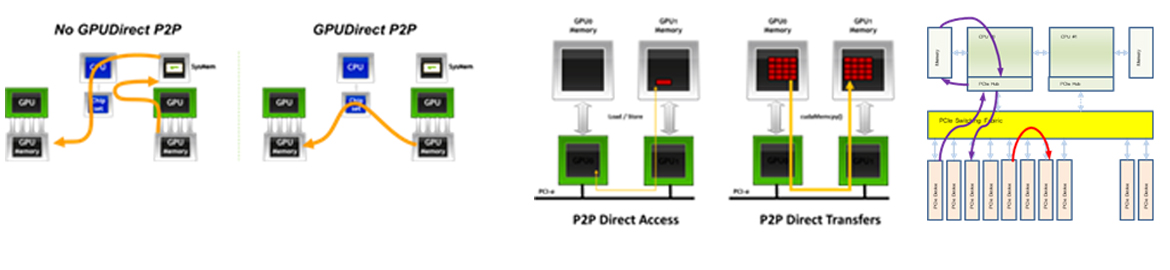
GPU Accelerating Computing vs. GPU Centric Computing