[HPC Architecture Development]
Conceptual Approach
There have been many studies on how to improve the performance of a single-node computer system. The bottom line is (1) improving processor performance, (2) increasing the number of processors, and (3) linking multiple systems.
Realistically, it is not possible to be in a position to improve the performance of processors under (1) and the clustering methodology, which increases the number of systems under (3), does not conform to the direction of the technology you are developing.
(2)'s plan already has a lot of research and results. In the early days, the technology of expanding the system bus to mount multiple processors on a board was realized, and later expanded to integrate multiple processor cores into one processor. But the market's demand is not a few times the performance improvement, but a few thousand times the performance improvement, which is less than the market's.
Considering that PCIe is not a bus system but a point-to-point network capable of channel bonding and that the GPU or FPGA installed in PCIe is used as an operating accelerator, we are confident that PCIe switching subsystem is a realistic way to improve system performance.
These large-scale connections have proven to dramatically improve the performance of a unit system. This can be considered as an Intraconation.
Realistically, it is not possible to be in a position to improve the performance of processors under (1) and the clustering methodology, which increases the number of systems under (3), does not conform to the direction of the technology you are developing.
(2)'s plan already has a lot of research and results. In the early days, the technology of expanding the system bus to mount multiple processors on a board was realized, and later expanded to integrate multiple processor cores into one processor. But the market's demand is not a few times the performance improvement, but a few thousand times the performance improvement, which is less than the market's.
Considering that PCIe is not a bus system but a point-to-point network capable of channel bonding and that the GPU or FPGA installed in PCIe is used as an operating accelerator, we are confident that PCIe switching subsystem is a realistic way to improve system performance.
These large-scale connections have proven to dramatically improve the performance of a unit system. This can be considered as an Intraconation.
Originated Method
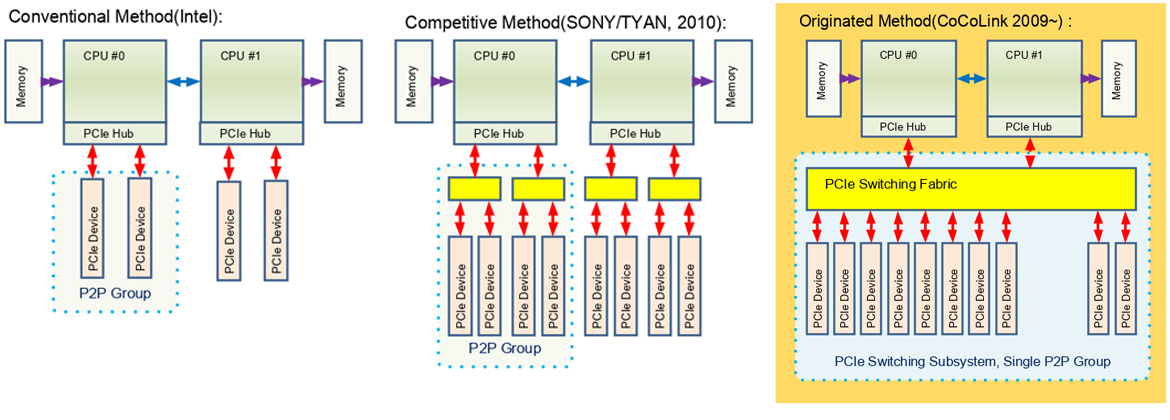
Unlike traditional systems, the Klimax-210 allows the PCIe fabric to be the backbone of the system, enabling the fitment of multiple PCIe devices, regardless of the type or number of CPUs.
In traditional systems, the number of PCIe slots was limited, and the PCIe slots were divided into two groups, limiting the direct data exchange (P2P) between different devices in the group.
In contrast, the Klimax-210 is connected to all devices through PCIe fabric in the 960Gbps bandwits, and establishes an ideal device connection structure that supports P2P between all devices regardless of the number of CPUs or enough device connections. For this reason, a single CPU can mount 20 PCIe x16 devices and there are no restrictions on how to use them. With these technologies, the Klimax-210 becomes a high-performance computing machine that no other system can match. In addition, these benefits can dramatically reduce overall system costs by reducing the number of CPUs and CPU boards.
In traditional systems, the number of PCIe slots was limited, and the PCIe slots were divided into two groups, limiting the direct data exchange (P2P) between different devices in the group.
In contrast, the Klimax-210 is connected to all devices through PCIe fabric in the 960Gbps bandwits, and establishes an ideal device connection structure that supports P2P between all devices regardless of the number of CPUs or enough device connections. For this reason, a single CPU can mount 20 PCIe x16 devices and there are no restrictions on how to use them. With these technologies, the Klimax-210 becomes a high-performance computing machine that no other system can match. In addition, these benefits can dramatically reduce overall system costs by reducing the number of CPUs and CPU boards.
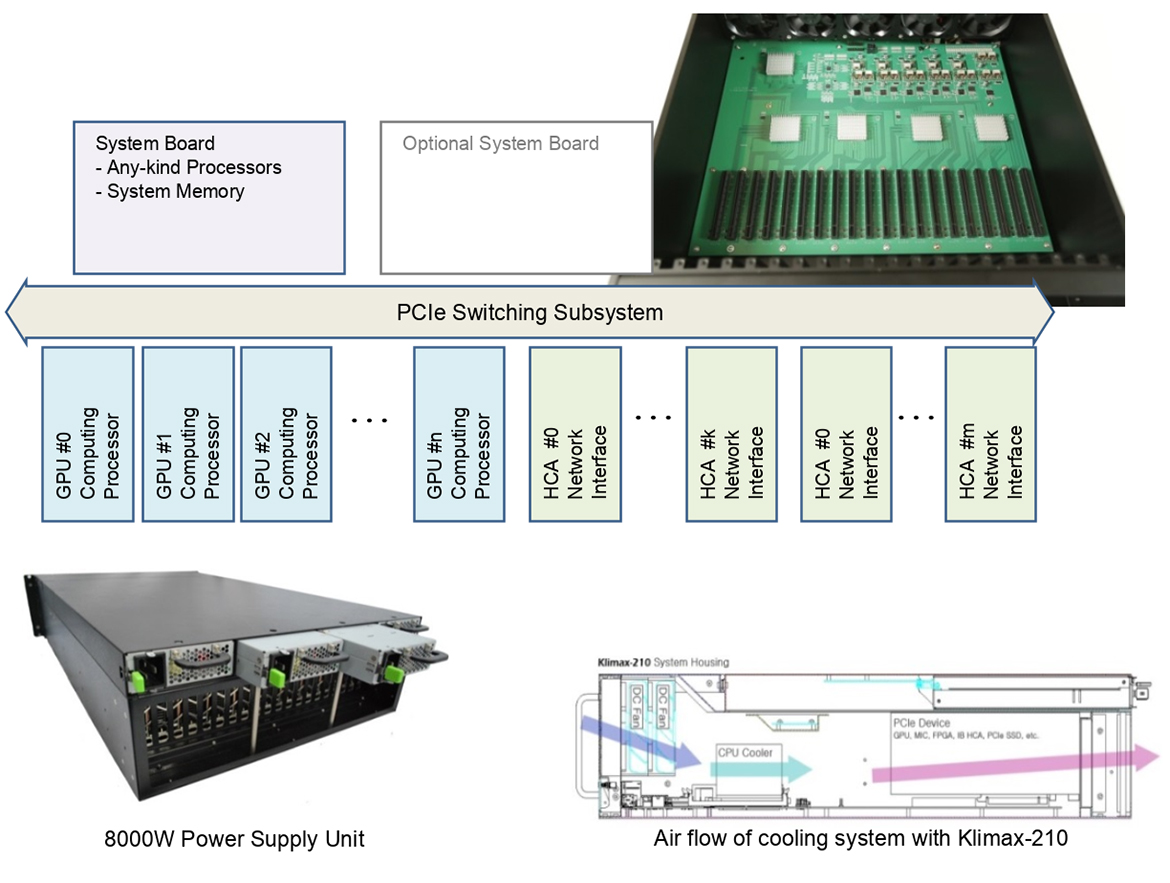
PCIe Switching Subsystem
Board to Board type of PCIe Switching Subsystem has been applied to Klimax-210 to maintain a very stable connection. The number of PCIe devices that can be equipped in a PCIe Switching Fabric has been remarkably expanded as well.
20 of PCIe Gen.3 x 16 slots are provided and powerful performance which was unthinkable in the conventional systems is now feasible by installing up to 20 of high-performance accelerating processors such as Tesla P100 PCIe.
20 of PCIe Gen.3 x 16 slots are provided and powerful performance which was unthinkable in the conventional systems is now feasible by installing up to 20 of high-performance accelerating processors such as Tesla P100 PCIe.
GPU Centric Methodology
To overcome performance degradation due to performance differences between CPU and GPU and data bottlenecks, the programming methodology computed only by GPUs ground.
Compact Design
On the inside of Klimax-210, system board, PCIe Switching Fabric board, space for 20 of PCIe devices and 8,000W Power supply are integrated in 4U form-factor to increase spatial efficiency.
10 of Klimax-210 can be equipped in 42" Rack allowing 0.3 PetaFlops per Rack to be integrated. Various equipment for convenience is available to maximize operational convenience.
10 of Klimax-210 can be equipped in 42" Rack allowing 0.3 PetaFlops per Rack to be integrated. Various equipment for convenience is available to maximize operational convenience.
Robust Design and Optimal Cooling System
Robust design for the system integration keeps the structure in a very stable condition using 8,000W(2,000W x 4). The 8,000W power supply will not fall short, even if the system has 20 units of GPU processors with highest performance which requires great power. This enables the system to maintain a stable status even though the system is operated with full load for a long period.
It has an efficient refrigerant flow that uses six 120mm fans for cooling. The six fans and thermo-fluid structure keep the internal temperature stable below 80 degrees Celsius even under high stress situations. If you need more stable cooling method, optional module which consists of 5 x 80mm fans is available. Also it was designed to apply white oil or fluorine container compounds without changing the structure.
Advanced Structural Design for compact form-factor and cooling High Reliability (No cabling)
It has an efficient refrigerant flow that uses six 120mm fans for cooling. The six fans and thermo-fluid structure keep the internal temperature stable below 80 degrees Celsius even under high stress situations. If you need more stable cooling method, optional module which consists of 5 x 80mm fans is available. Also it was designed to apply white oil or fluorine container compounds without changing the structure.
Advanced Structural Design for compact form-factor and cooling High Reliability (No cabling)
[Optimal Programming]
CPU vs. GPU
CPU has SISD structure or parallel MIMD structure, and some newer CPU processors have applied vector engine to ALU to improve performance, which is highly mechanical but very difficult to increase computational performance efficiency when programming. More processor cores make it more difficult to increase performance efficiency.
GPU is also referred to as SPMD as a high-efficiency processor that enables operation similar to MIMD by flexibly improving the existing Vector Processor, a SIMD structure. More sophisticated programming than CPU enables performance efficiency. Generally, CPU and GPU with the same theoretical performance differ by more than 10 times.
GPU is also referred to as SPMD as a high-efficiency processor that enables operation similar to MIMD by flexibly improving the existing Vector Processor, a SIMD structure. More sophisticated programming than CPU enables performance efficiency. Generally, CPU and GPU with the same theoretical performance differ by more than 10 times.
GPU Accelerating Computing vs. GPU Centric Computing
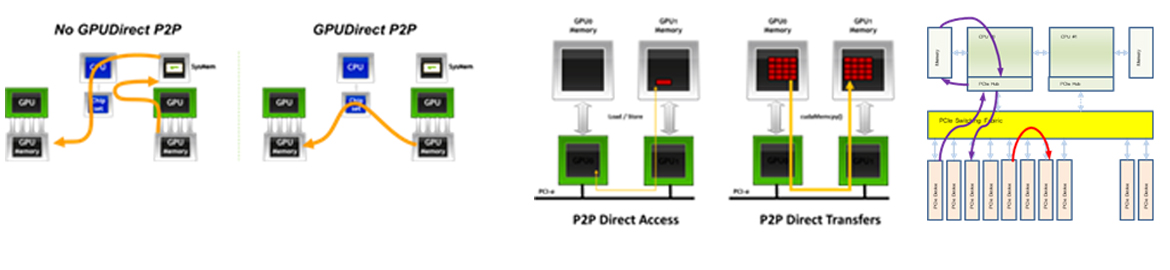
GPU Accelerating Computing is basically CPU processing and some high-throughput operations are handled by GPU, which consumes a lot of resources to transfer data between CPU-GPUs, resulting in significantly lower overall performance efficiency.
GPU Centric Computing is very beneficial to maximize program performance by excluding relatively low-performance CPUs from the operation, as GPU handles all operations and only I/O and program control functions are handled by the CPU.
GPU Centric Computing is very beneficial to maximize program performance by excluding relatively low-performance CPUs from the operation, as GPU handles all operations and only I/O and program control functions are handled by the CPU.
GPU Centric Computing over PCIe Switching Fabric
If GPU Centric Computing's methodology is operated on systems with multiple GPUs, sending data directly between GPUs can help you configure an extremely performance-efficient computing environment.
With the ability to 'transfer single block of P2P data' between any GPU, SSD, or HCA mounted on the system, the Klimax-210 is the only system that enables the ideal programming environment, GPU-based GPU-based GPU-based GPU-based, multi-GPU-enabled
With the ability to 'transfer single block of P2P data' between any GPU, SSD, or HCA mounted on the system, the Klimax-210 is the only system that enables the ideal programming environment, GPU-based GPU-based GPU-based GPU-based, multi-GPU-enabled
Futuristic Environment for Exa-scale Super-computing
When GPU Centric Methodology and PCIe Switching Fabric are applied, current GPU technology alone makes it easy to deploy 1 ExaFLOP-scale systems. Furthermore, you can increase the performance efficiency of your existing systems below 10% to over 50%, so you can actually benefit from systems with 10 ExaFLOPS performance.
CoCoLink Sugests GPU Centric Computing Methodology
CocoLink is the company that proposed this methodology in GPU Centric Computing methodology and has the highest competency.
GPU Accelerating Computing vs. GPU Centric Computing